

By Rafael Aguayo
Edited by Jordi Cabré
Part I
Let me start by saying there are many competent quality practitioners using the term Six Sigma. I have a great deal of respect for many of these experts and do not disparage any of them. Of course like any field there exists a huge range in the level of skill, knowledge and wisdom among practitioners, from the novice posing as an expert to the polished professional.
The Six Sigma campaign has been a marketing success. Many people have been exposed to process improvement and undoubtedly many companies have benefited. Still the original theory that led to the term Six Sigma has some critical flaws that can only lead to confusion. The theory conflicts with key tenets of Shewhart and Deming with respect to variation and management. I would like to bring those out here to stimulate discussion. The ideal would be to conserve the best aspects of Six Sigma but place it on a firm footing with a system of profound knowledge.
The term Six Sigma can refer to a basket of tools used to track down problems and defects and improve processes in an operation. My concern here is with the actual name Six Sigma, as I think the original theory developed by Motorola is mistaken and will lead to loss. The more experienced Six Sigma professionals do not rely on the original Six Sigma tool, but instead use process improvement tools developed in the U.S., Japan and other parts of the world over the last 150 years. To explain my objection to the name “Six Sigma” we need to understand the basic principles of statistical process control and how and why they were developed.
Understanding Variation
The story begins at the Bell Laboratories of AT&T in the 1920s. AT&T was the largest phone company in the US, probably the world, and they also had a huge manufacturing operation to service their network. They had access to the best minds and the best consultants of the day including Frederick Taylor the developer of what would become industrial engineering. The company sought out the best minds, employed brilliant engineers, scientists and mathematicians and created a great environment to work. Despite this leading edge expertise and knowledge there was a problem they could not solve.
AT&T promised customers uniformity, each phone was to be just like the last. Yet the more they tried to achieve this, the worse the results. A young physicist, Walter Shewhart, was assigned the problem. Shewhart pursued this riddle. He thought, experimented, read the literature on statistics and developed new concepts, theories and terminology that proved to be extremely powerful and useful.
Natural Variation
He found that in a process there are two kinds of variations. One kind is inherent in the system and he called this natural variation. If you use your best efforts to eliminate variation by making the process as uniform as possible with each step being performed exactly alike you would still have this inherent natural variation. Visual control, visual attempts to make the process uniform will take you so far and no further.
Natural Variation and Tampering
Natural variation will occasionally cause a large amount of variation in the end product. The natural reaction of most people when this happens is to adjust some part of the process: a machine setting, room temperature or some other factor. But the underlying process has not changed; the average or center point has not changed, so on the very next try the process could produce an extreme in the other direction. As an example suppose a process produced an output with an average measure of 98 with variation from 97.5 to 98.5. At one point it happens to produce an output of 98.5 at the top end of natural variation. We might be tempted to adjust the process mechanisms down by .5 since the ideal outcome is 98.00. The thinking is that the process has shifted upwards excessively and therefore we have to adjust it downward. But the higher results of 98.5 was just the result of natural variation, nothing special happened at all yet we treated it as such and made an adjustment. What we have done is to re-aim the process. Now from hereon in the process will produce at an average of 97.5 with a range from 97 to 98.0. If at one point we get a result of 97, something that is bound to happen, we are forced to make another adjustment. Left alone the process would produce between 97.5 and 98.5. With adjustments the process will have a much wider range, maybe from 97 to 99.0 or even greater. A process that is stable will have a fairly predictable range and it will continue to produce product or deliver a service with the same mean or average. But every now and then it will produce an extraordinary value outside its usual range. What should we do? Anyone with experience will tell you that processes tend to deteriorate. They follow the second law of thermodynamics or one or more of Murphy’s laws. Therefore we need to monitor any process. But we need to be very careful to leave a process that exhibits natural variation alone unless we get a real signal that something has changed.
A process that is stable will have a fairly predictable range and it will continue to produce product or deliver a service with the same mean or average. But every now and then it will produce an extraordinary value outside its usual range. What should we do? Anyone with experience will tell you that processes tend to deteriorate. They follow the second law of thermodynamics or one or more of Murphy’s laws. Therefore we need to monitor any process. But we need to be very careful to leave a process that exhibits natural variation alone unless we get a real signal that something has changed.
Assignable Causes
There is a second kind of variation, which Shewhart said had an assignable cause. That is to say that they were caused by something unusual that could be identified and probably eliminated. And further most of the time they could not readily be seen. Sometimes these causes entered the system caused a problem or increased variation and then exited the system. But the fact that they had entered the system means they could enter it again and cause havoc. Often assignable causes are early warning signs of the process deteriorating. There might be a bearing starting to fail, a new employee being untrained or improperly trained or a supplier changing his process. If you could identify these causes and eliminate them, you could further improve the system and allow it to run at its economic maximum.
Another assignable cause is when the process shifts its aim. In our first example the process produced product between 97.5 and 98.5 with an average of 98.00. The process had an aim of 98.00, that was the ideal measurement. The spread can widen so that the range moves from 1 to say 1.5. But the process can also shift so that it is no longer aimed at 98.00 but instead at, say, 98.3. Either one of these occurrences is a problem that will lead to loss and you need to be able to identify when they occur so that you can take action to correct and improve. At the same time you do not want to confuse normal variation with either of these assignable causes.
Modern Terminology
Natural causes are now called common causes and assignable causes are referred to as special causes. There are two kinds of signals that are important from the point of view of quality and uniformity:
1. A change in the average of a process and
2. A change in its range.
There is no absolute foolproof way of determining whether something is a special cause or a common cause. The two both produce variation so we need to think statistically. We can search for a special cause and find one and eliminate it. This is an ideal outcome. But we can search for that special cause and after much work not be able to find anything to explain the variation. We made a mistake, the cause was common and we treated it as being special in nature and there is cost associated with this mistake. There was no benefit but someone had to take time to search for it, may have run some experiments, may have questioned others and time was taken away from other useful activities. Shewhart initially called this a type I error, but we now call it a type I mistake. There is a cost in time and money associated with a type I mistake.
On the other hand we could see a large change in the mean or the range of a process and ignore it and it turns out it was just natural variation and the process is operating fine. This is ideal. But if we ignore a change and it turns out there really has been a change, a special cause has entered our system and this can cause many more expensive problems in the near future. There is a cost to ignoring a special cause and we now call this a type II mistake.
How Were 3 Sigma Control Limits Determined?
What Shewhart had to do was minimize the loss from these two kinds of errors. One could eliminate type I errors by making many type II errors and vice versa. But he needed a robust way of minimizing the total loss from both kinds of errors for many different kinds of processes. To do this he developed Control Limits. What he found through observations and experimentation over a broad range of processes in many areas of business was that if the control limits were set at 3 sigma they seemed to work. Three sigma control limits minimize the loss from making these two types of errors. They were empirically determined. And they have held up remarkably well over the 80 years since Shewhart published his first book. No one has found a better way.
3 Sigma Control Limits are computed in the same way that standard deviation is computed, but the term 3 sigma is better. People who hear the term standard deviation automatically assume that the underlying process distribution is a normal distribution but it is not. At one point it was thought that once a process is in statistical control, meaning there are no special causes at work, the underlying distribution would be a normal distribution. When that failed to be the case it was hoped that a family of distributions might fit the data, but as Shewhart stated in 1939 all hope for that has been shattered.
This turns out to be very upsetting to many people who confuse mathematics with reality. A further explanation might require a lengthy article but for now I just wish to point out that a normal distribution assumes specific ideal conditions with no environment. Alas reality is not so simple.
Returning to the main topic, however, once we remove all special causes our process is said to be in statistical control. Of course it has to be monitored to preserve that state as statistical control is a very unnatural condition that requires effort and vigilance to maintain. But suppose our process has a mean of 98.00 as stated above and s range of 97.5 to 98.5. What is the defect rate? Which are the defective products?
Voice of the Process, Voice of the Customer
The surprising answer is that from what we have covered so far there is no way of knowing. All we have discussed so far is the process. The process if it is in statistical control has a capability. It has an average that persists over time and it has a spread that persists over time. This is called the voice of the process. But whether the output of this process is good, within specifications, defective or fit for use depends on outside considerations.
What will the product be used for, how will it be used and what are the requirements of the user. It is a statement about the environment, the larger system in which the product of our process is but a part. In a production system, or a service system the user or customer is the next step in the process. This is the voice of the customer. The traditional way of stating fit for use of a product are specifications.
If the specifications are that the product (or service) should have a mean (or ideal) of 98.00 and a range from 97.00 to 99.00 then everything produced by our process is good. If the required range (specification) is 97.5 to 98.5 then we will occasionally have defects as it is possible though rare that our process will produce sometimes outside this range. But if the specifications are tighter such as 97.75 to 98.25, then we have a major problem as our system will produce many defective items. In the last two cases those who manage the process need to focus on decreasing the range of the process. This is done not by adjustments which as has been stated will increase the variation, or by edict but by lessening the common cause variation in the process. For a stable system, that is to say one that is in statistical control, this requires improvements in the system. A control chart is invaluable for systemic improvements as well as for eliminating special causes.
X-bar R charts
To show how this works in practice we will generate control charts using 40 data points. Those who understand control charts may want to skip this section. If you have no knowledge of control charts this section might help but it cannot replace the many complete and comprehensive books available concerning control charts.
The data for this example was taken from a plant that had been using control charts for decades. The process is so tight that the specification limits are many times greater than the 3-sigma process limits or control limits. The process could go badly out of control and yet not produce a defect. Nevertheless the principles for the use of control charts are the same for processes that are not so well developed. Control charts can be used for products or services. They can be used to monitor sales or almost any other aspect of your business.
In our current example four measurements are taken each day at 10 am, 12 noon, 2 pm and 4 pm. We have 10 days worth of data for a total of 40 points of data and 10 subgroups. The data for each day are grouped together and form what Shewhart called a rational subgroup. Each subgroup has an average, which is merely the arithmetic average of the four data points and a range, r, which is the difference between the largest measurement in the subgroup and the smallest. From the forty points we obtain 10 averages and 10 ranges and this allows us to draw an X-bar chart, R-chart.
X refers to each actual measurement. Here we have 40 values of X. X-bar is the average for each subgroup. We have 10 values for X-bar. X-double bar is the average of all 10 X-bars. We have just one X-double bar and this is the center line of our control chart.
R is the range for each subgroup and we generate 10 values for r, one each day. R-bar is the average of the 10 r values. It represents the average range for the 10 day period and we have just one value.
Below is a spread sheet with the 40 values, the averages and the control limits for each chart.

Here UCL means Upper Control Limit, LCL means Lower Control Limit. The center line for X-bar is the average X-double bar or 15.8940. The UCL is 15.9217, while the LCL is 15.8663. For r the UCL is .08671, while the LCL is 0. The process is very tight. We can examine the numbers to see if any point is out of control, but a control chart makes the recognition instant. Below are the control charts for this process.
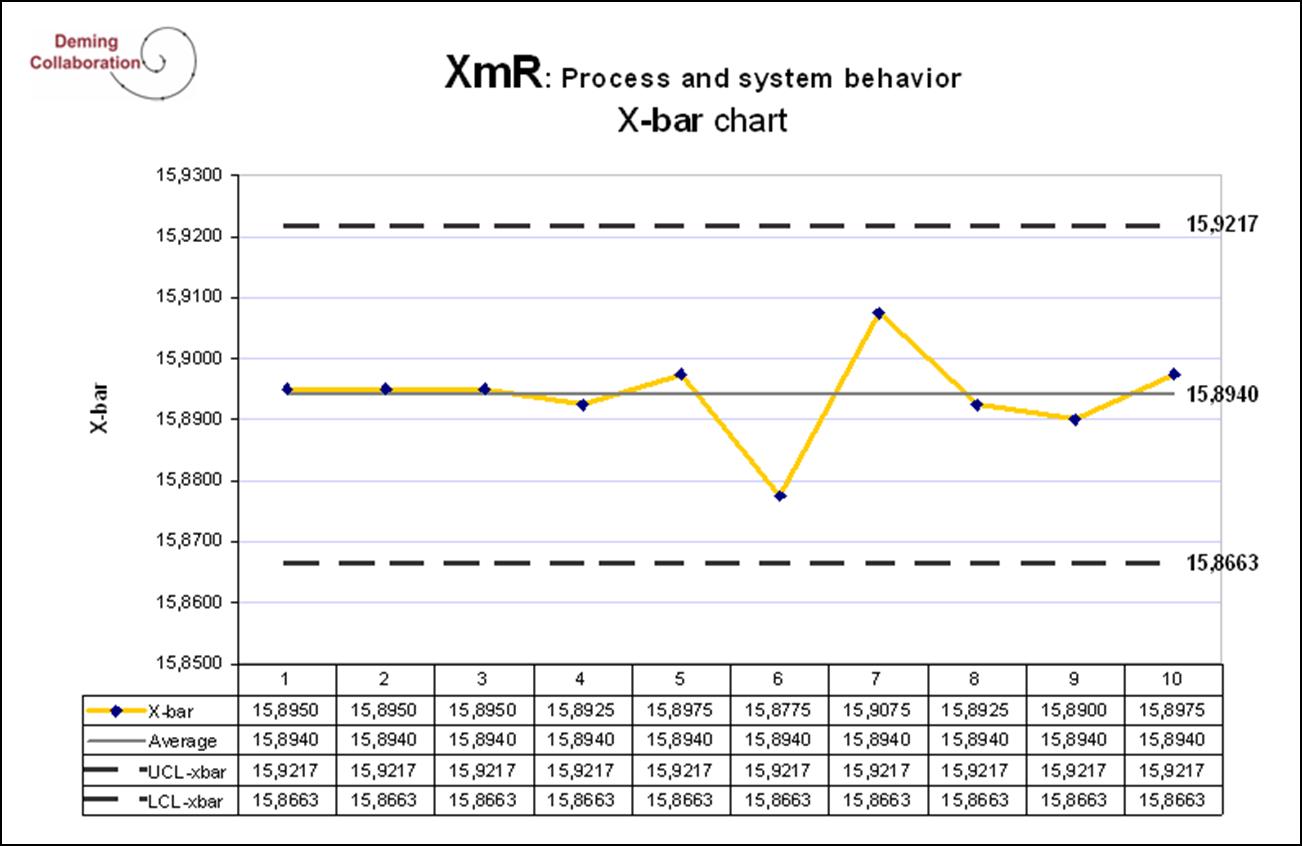

These two control charts give us a very accurate, intuitive and immediate view of the process. Any points that are out of control show up immediately. We have two charts which gives us an immediate and very sensitive indication of the aim of the process and the spread of the process. Were the process aim to change we could spot it quite rapidly. At the same time phantom moves in the aim which are due to just natural causes are filtered out. The control chart helps us distinguish a real signal from noise. The same is true for the r chart which gives us a statistically significant and sensitive indication of the spread of the process.
The control chart tells us that there has been no significant change in the aim or center of the process. All the points for x-bar are within control limits and there are no recognizable patterns. But the chart shows that on day 7 the range went out of control. The charts give a clear signal that something has changed and we need to determine the cause of that spike. How should we handle this situation?
Control charts cannot tell someone the source of the problem and we don’t want the control chart expert dictating what to do. Instead the subject matter experts, the people working on the process, the engineersandmanagersmustbeallowedtobringtheirexpertisetobearontheproblem. Properlyused control charts are a management tool that allows for the exercise and development of the creativity and knowledge of the people in the company. It prevents people from searching for phantom problems and if properly used focuses the efforts of the people in the company on improvement. This can have a palpable effect on confidence, fun and joy for the people in the company.
Improperly used they do harm. A manager who insists that the process get back into control or who arbitrarily sets targets for the control limits will ruin a company. Using fear, excessive targets or firing the bottom 10% are not just bad management that will lead to ruin, they are examples of gross ignorance of variation and managerial negligence.
Part III
The Theory Behind Six Sigma
“Six Sigma is the relentless and rigorous pursuit of the reduction of variation of all critical processes to achieve continuous and breakthrough improvements that impact the bottom line of the organization and increase customer satisfaction.” This is a wonderful boilerplate statement that would be difficult to take issue with if it were done correctly with great understanding of an organization; In other words with Profound Knowledge.
Six Sigma assumes that the average firm produces defects at a rate of 66,811 defects per million opportunities. Its goal as an organizational initiative is to create manufacturing, service, and administrative processes that produce approximately 3.4 defects per million opportunities (DPMO). These statements are noble but they raise questions.
I. How is the current defective rate of 66,811 defects per million determined?
To justify this statistic several assumptions are made: 1. Six Sigma theory assumes the average firm has its processes in control (sort of) with process limits of 3 sigma and the specification limits are set at exactly the same 3 sigma level.
2. It assumes that the distribution of variation about the mean is normally distributed. These are major assumptions and we could discuss each at length but for now we are just stating the assumptions so let’s continue. The result is a process distribution that looks like the chart below.

Here LSL means Lower Specification Limit and USL means Upper Specification Limit. In this chart the process limits equal the specifications.
The beauty of a normal distribution is that it is simplistic and calculations are easy. All symmetrical normal distributions are the same. If you have seen one you have seen them all. And with just one statistic, Z, you can calculate the percentage of the distribution that is inside the curve. This is undoubtedly one reason why they are used so much in finance and now in Six Sigma. But being easy to calculate does not make a function accurate.
Those who have taken a course in statistics may recognize the number of sigma lengths from the mean as being the Z value. We define Z here as the number of standard deviations from the mean of a normal distribution. Z = [X-average] / sigma
One Z is equal to one standard deviation length from the mean. In this context one Z is equal to 1 STD.

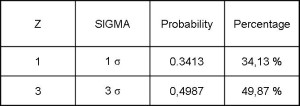
The term sigma is a broader term that can be used for any distribution. In this context, with a normal distribution, however, 1 sigma = 1STD = a Z of 1. The chart shows therelationship between Z (or Sigma) and the area underneath the normal curve. The area underneath the curve is the probability that outcomes fall between the mean (zero on the graph) and Z.
For 1 sigma the probability is .3413. For 3 sigma the probability is .4987. This means that 49.87% of the time the distribution produces results between the mean, which Six Sigma calls the Nominal Value, and the 3 sigma length. But Z refers to just one half of the distribution. To determine how many points fall within Z=3 on either side we have to double the probability to .9974. This says that 99.74% of the time the output will be within 3Z on either side of the mean or center value. 99.74% of the time the process produces within specification, while .27% (1-.9974) of the time it is outside of specifications. This is 2,700 defects per million.
II. Additional Assumptions: But Six Sigma goes on to make another dubious assumption. It assumes that all process means shift 1.5 Sigma in each direction. From the point of view of Statistical Process Control, this is an incredible assumption. How anyone could determine this holds true for all process or even many processes is unknown. But the implication is that the processes are grossly out of control. Just using a simple X- bar R chart one can quickly determine when a mean is going out of control. Corrective action can be rapidly taken to discover the causes of much smaller shifts in the mean. And the causes can and should be eliminated. With this kind of vigilance not only is the process prevented from shifting, but improvements are constantly made to the system making future shifts even more unlikely.
But Six Sigma theory assumes that the mean shifts back and forth neatly 1.5 sigma in each direction and nothing more need be done about it. Further it still assumes a normal distribution, a truly incredible assumption. A normal distribution might be a possibility if the system were under statistical control. But to assume it is the case when the system is grossly out of control takes more than a leap of faith. Below is a picture illustrating this:

Six Sigma theory implies that one can have a stable system that is grossly unstable. An unstable stable system: clearly a contradiction. Unstable systems (and one that shifts 1.5 sigma is unstable) are not predictable. They can swing quite wildly, even chaotically. But given these mathematical assumptions a normal distribution with a 1.5 sigma shift and a 3 sigma specification limit from the nominal value, will produce , according to the Six Sigma story, 93.33189% within specification limits and 6.6811 % defective or 66,811 defects per million. Under such wild conditions to assume such accuracy defies logic and experience. It implies a simplistic view of the world and the very concept of probability. Probability theory in Six Sigma is used to make exact predictions; naïve in the extreme.
3. But let’s do the mathematics to compute the actual long term percentage defective under these assumptions.
a) Six Sigma assumes that the process has a 3 sigma distribution and the specification limits are also set at 3 sigma.
b) In addition the process shifts by 1.5 sigma in either direction. In other words the process shifts out to 4.5 sigma in either direction.
c) The distribution follows a perfect text book, normal distribution.
So let’s compute the fraction that is inside the 3 sigma specification limits. From that we can compute the amount that are outside specifications and therefore defective.
– It is unclear just how this process shifts. Is it a linear function moving back and forth? Is it a normal function? Is it stuck on one of the two ends, a most unlikely scenario?
– To do the calculation we will assume a very bad scenario. The process spends 1/3 of the time out at each end and 1/3 of the time right in the middle, as per the above graph.

When the process shifts out to one end its Z value on one side is 4.5Z while on the other end it is 1.5Z relative to specifications. The Z value of 1.5 is .4331, while the Z value for 4.5 is .49999. Thus .9331 is within specifications. This represents the worst scenario when the process is at the extremes of its movements. We are assuming a worst case with the process spending 2/3 of its time at these extremes so we need to weigh this value by 2/3 (~0.67) to get (2/3*.9331) = .6220: 2/3 * .9331 = 0.6220
The other third of the time the process would be in the middle of its drift. It would be a 3 sigma process with a 3 sigma specification limit. We have already computed above the combined Z values for these and it is .9974. Multiplying this by 1/3 (~ 0.33) results in .3324.
1/3 * .9974 = .3324
Adding both: .6220 + .3324 = .9544; (1 – .9544 = .0456)
This results in a percentage defective of 4.56% or 45,614 defects per million. This differs considerably from the standard Six Sigma hyperbole of 66,811 defects per million. The only way this latter figure makes sense is if the process sits at one end of the extreme and then shifts to the other end at the speed of light. Unfortunately even the arithmetic of the Six Sigma is wrong.
Where did this 1.5 Sigma shift in the process come from? It seems to have been made up. David Wayne, director of Quality & Process improvement at Motorola Broadband Communication Sector believes it represents a fundamental misunderstanding. A 1.5 sigma shift was suggested in the 1950s in the “context of tolerancing assemblies of components.” As he states: “This is fundamentally different from allowing for such a shift in the process mean of individual components.” In other words the 1.5 sigma shift seems to represent a confusion between designing for variation and process variation. And as he goes on to state a control chart is designed to eliminate shifts in the mean.
This article can be accessed at Curious Cat websites through this link: See article.
The article very competently covers major areas of difference between Six Sigma and the Deming school of quality.
I may be a skeptic but it does not escape me that a 1.5 sigma shift makes the “average” company appear to be much worse off than it actually is and that can be helpful in marketing. But no company with a nearly 7% defective rate could possibly survive even in the America of 1984, where quality was terrible. What Six Sigma really must assume to make its numbers work is that the average process has a spread of 4.5 sigma and the specifications are set at 3.0 sigma. Under these conditions of course no business could survive.
But why the big concern with an artificially induced shift in the mean? After all, this is more or less the before picture of a poorly run company. Surely one of the benefits of Six Sigma would be elimination of this shift and therefore the generation of much improved quality. Alas, that is not the case. Six Sigma assumes the 1.5 sigma shift is permanent and exists in all processes. The goal then is to shrink the variation of a 4.5 sigma process so that the specifications limits represent 6 sigma and this leads to 3.4 defects per million, as

To put this into a quality perspective, if the process were to obtain statistical control, the 4.5 sigma process level must be considered as 3 sigma. Mathematically this means multiplying all the sigma values in the above example by 2/3. The 6 sigma specification levels when corrected is 4.5 sigma (6 * 2/3). This gives a defect level of 3.4 per million. Six Sigma should really be called 4.5 Sigma.
Statistical Process Control has been using a capability ratio for decades. Essentially this is the distance from the upper specification limit to the lower specification limit divided by the process length normally expressed in sigma.

In the 4.5 sigma example above the total specification length is 9 sigma (4.5 on each side) while the process limits length are 6 sigma (3 on each side) for a capability ratio of 1.5. This is the ultimate promise of Six Sigma. While this may seem impressive much higher capability ratios have been experienced by companies that have been using SPC for years. A capability ratio of 3 would be equivalent to 9 sigma (9+9/3+3 = 9/3 =3.0)[i]. (To fully express this in Six Sigma terminology we need to multiply 9 by 3/2 to arrive at 13.5 sigma.)[ii] Many Japanese companies had achieved that capability level during the mid 1980s. Doing the math for a capability ratio of 3 with the Six Sigma assumptions of a normal distribution leads to 0 defects per hundreds of billions. Six Sigma, in other words, was obsolete at its inception.
Other Issues
DMAIC
It is possible that practice differs from theory. Maybe Six Sigma practitioners are focused on process improvement and lowering variation. However, the techniques that are emphasized in Six Sigma do not seem to acknowledge natural variation nor the need to minimize variation.
One of the basic tools in the Six Sigma toolbox is DMAIC, which stands for Define, Measure, Analyze, Improve and Control. The demonstrations I have seen of this tool indicates it is used to cut costs but not to lessen variation or improve quality. Unfortunately too often Six Sigma has become a justification for cost cutting with all the inherent problems and negative results associated with that.
Some of the problems associated with cost cutting are dealt with in other parts of the Deming Collaboration website which the reader can access through these links: Videos on Cust Cutting ; Necessary Warnings and Decisions making
Apparently Six Sigma was not used to improve variation among the elite firms that used it. In The GE Way Field Book, Robert Slater who had direct access to Jack Welch documents that after years of using Six Sigma customers did not notice any improvement.In one example the company had lessened the average delivery time of a major product by several days but the variation in the process was so extreme that customers could experience almost as much variation as in the past. This meant that they could not plan into the future and GE continued to be seen as unreliable.
Building a Science
Any discipline, and that includes history, science, art, mathematics, music, medicine, engineering and physical training to list just a few, builds on the work of prior masters. The astronomer who, unfamiliar with the work of Johannes Kepler, presents a theory that the earth actually rests on a giant turtle might get some US politicians to support the idea, but among astronomers, both amateur and professional, he would be greeted with howls of laughter.
For us at Deming Collaboration quality and management are treated as a science with a rich history. Deming masterfully taught Shewhart’s insights. This was only possible because he spent years understanding and mastering Shewhart. And just as Shewhart and Deming had antecedents, others have built upon their work and become masters in their own right. Among these are Ishikawa, Taguchi, Chambers, Wheeler and others. It is our intent to build on this body of knowledge. We may at times disagree with the work of others, but we will be careful to understand it and respect it before commenting.
The Desire for the New
Business, however, at times appears quite different. People touting the next new thing, an idea out of the blue that they invented through a stroke of genius, are constantly trying to sell their wares and make millions through book sales, seminars or consulting. And from time to time some are successful doing just that.One major problem, however, is that these people cannot avail themselves of the wonderfully effective ideas that have been developed over the years by people in the discipline. Among the areas where SS theory appears to be lacking because it cannot make use of prior masters are the following:
- Lack of concern for external quality. In The Deming Prize, written by Kenichi Koyanagi in 1960 and published by The Union of Japanese Scientists & Engineers, the author in discussing Deming’s 1950 visit to Japan writes, Dr. Deming also stressed the broad concepts of statistical quality control from tests of raw materials to the consumer research by which the product is designed and redesigned to meet the needs of the consumer and his pocketbook.”Thus was introduced to Japan quality from the point of view of the consumer as well as the famous Shewhart Cycle, which became known as the Deming Cycle or PDCA (now PDSA) that would later become Kaizen.Six Sigma seems to completely ignore the customer. The reality is that DMAIC and the other SS tools are completely unsuitable, even counterproductive for consumer research.
- Lack of appreciation for improving processes, especially critical processes even when they are well within specifications. Genichi Taguchi, a multiple winner of the Deming Prize in Japan, created the important concept of the loss function and critical parts and processes. Even when a process is functioning well and without defects identifying criticality can produce marvelous results and help strengthen the bond between customer and company. Companies without this knowledge are at a distinct disadvantage.
- Lack of management appreciation of the need for participation. Deming emphasized joy in work, teamwork and listening to your people. This seems to be totally lacking in Six Sigma. In fact major SS practitioners emphasize practices that will destroy teamwork, company
cohesiveness and pride. Among these practices are fire the bottom 10% and rewarding for the achievement of strict numerical targets.
• Failure to appreciate the company as a system. Making improvements to one variable, such as material costs, can lead to higher labor costs.Lowering costs in one department can lead to higher costs overall for the company. These mistakes can be avoided if one understands the systemic nature of a company. The poster child for this is Motorola. Motorola claims to have saved $12.5 billion through its Six Sigma initiative. As Deming so aptly stated it is possible to have zero defects and zero customers. Recently it separated into two companies. The original, better known communication equipment division that included its former jewel, the cell phone handset manufacturer, became Motorola Mobility (MM). Recently Google purchased Motorola Mobility. MM had a total stock market valuation of $6 billion. Google paid twice that or $12 billion. The patents were worth $6b, the company had $3b in cash and tax loss carry forwards that were worth well over $3.5b to Google. Google in effect, paid less than zero for the operating company, all its logos, its name and goodwill.
This is a partial list of what SS is missing relative to the quality movement and Deming.
The Main Problem with Six Sigma
In business theory pales in comparison to results. If Six Sigma has had wonderful results in practice then bad theory may be irrelevant. But experience teaches that good theory allows a competent professional to have good long term results. Bad theory will have a destructive effect, certainly in the long run. And the results from companies who have touted and used Six Sigma are not good. To my knowledge there are no long term successful companies who have claimed to use Six Sigma. In fact there have been several dramatic failures.
Robert Nardelli was one of three superstar GE executives in the final cut to succeed Jack Welch as CEO. When he lost out to Jeffrey Immelt, he was snatched up by Home Depot’s board. He quickly brought his Six Sigma magic along. He focused on cost cutting, and outsourcing personnel functions. Some costs declined and profits increased. He cut back on services and customer classes. Customers began going elsewhere. Lowe’s was up and coming and began pulling customers away. Home Depot’s stock share price stagnated. While customers were leaving shareholders were up in arms. Within a few years of being hired Nardelli was fired but his contract called for him to receive hundreds of millions of dollars. He then brought his Six Sigma magic to Chrysler with even more disastrous results.
NT, formerly Nortel and before that Northern Telecom was touted as a successful Six Sigma company. They entered bankruptcy and have since been liquidated. The most valuable part of the company was the patent portfolio which sold for $4 billion due to the competition between Apple, Microsoft and Google.
Two companies perennially mentioned as successful Six Sigma companies are Motorola and GE. Motorola Mobility has agreed to sell itself to Google for $12.5 billion. With cash on hand of $3 billion, patents valued at $6 billion and tax loss carry forwards well in excess of $3.5 billion and which it could not use unless it started making a profit, the actual operations of Motorola Mobility was valued at less than nothing, hardly a rousing success.
That just leaves GE. But GE has recognized the problems with Six Sigma and abandoned it. It would be unlikely they would completely drop the name since GE earned hundreds of millions of dollars preaching and teaching Six Sigma to other companies and institutions. They are now using something they call Lean Six Sigma. An investment in GE in the late 1990s has lost around 80% of its value. Is this success?
Conclusion
My conclusion is that as it currently formulated Six Sigma will continue to have major problems. Every company requires Profound Knowledge to experience lasting success.
[i] Remember that most of the time we are talking about half the spread. In SPC 3 sigma is measured from the mean to one end of the process. The total spread of a process is 6 sigma. The total spread of a process in Six Sigma is 9 sigma.
[ii] SPC theory indicates that anywhere from 95% to 100% of a stable process is within 3 sigma limits. Shewhart, who had the resources of the Bell Laboratories to run numerous tests and experiments, found that a stable process had close to 100% of its output within 3 sigma limits. A result outside of 3 sigma was therefore a strong signal of anassignable (or special) cause. Six Sigma assumes all processes have a spread of 4.5 sigma. To move from one view to the other we must multiply Six Sigma spreads by ? to have an equivalent SPC spread. To move back from SPC to SS we must divide by ?, which is equivalent to multiplying by the multiplicative inverse, 3/2. This is just to compare mathematically the two theories. It is not meant to imply that the two views are equivalent. In fact they are very different philosophically and otherwise.
Further Reading
Anthony D. Burns Ph.D. – Quality Digest
Download a PDF of Why I dislike the name Six Sigma Here